
本博客介绍SPTAG在搭建时看过的有用的博客,及使用时遇到的问题
1.功能
SPTAG是微软在2019年2月左右开源的一个用于向量搜索的工具。github官方网站。
搜索速度快,200万数据,向量768维度(BERT和ERNIE输出向量都是768维)情景下,搜索一速度为5ms。
本博客记录我使用SPTAG的一些总结,包含SPTAG安装,与使用时遇到的问题。
2 安装
SPTAG 的github上说只要swig、make、boost三个库,但是在装boost的时候还提示说需要intel的TBB。 具体版本为:
- swig >= 3.0
- cmake >= 3.12.0
- boost >= 1.67.0
- tbb >= 4.2
2.1 Ubuntu和Deppin
安装好后,如果不能使用boost的库:https://blog.csdn.net/zx7415963/article/details/46845161
Linux查看boost版本 dpkg -S /usr/include/boost/version.hpp
SPTAG:如果要使用python3编译,则要修改Pythonwrapper目录下的CMakeList.txt文件,调换python2和python3检查的顺序
find_package(Python3 COMPONENTS Development)
if (Python3_FOUND)
include_directories (${Python3_INCLUDE_DIRS})
link_directories (${Python3_LIBRARY_DIRS})
message (STATUS "Found Python.")
message (STATUS "Include Path: ${Python3_INCLUDE_DIRS}")
message (STATUS "Library Path: ${Python3_LIBRARIES}")
set (Python_LIBRARIES ${Python3_LIBRARIES})
else()
message (STATUS "Could not find Python 3!")
find_package(Python2 COMPONENTS Development)
if (Python2_FOUND)
include_directories (${Python2_INCLUDE_DIRS})
link_directories (${Python2_LIBRARY_DIRS})
message (STATUS "Found Python.")
message (STATUS "Include Path: ${Python2_INCLUDE_DIRS}")
message (STATUS "Library Path: ${Python2_LIBRARIES}")
set (Python_LIBRARIES ${Python2_LIBRARIES})
else ()
message (FATAL_ERROR "Could not find python2 or python3!")
endif()
endif()
- 编译SPTAG
mkdir build
cd build && cmake ..
make
- 使用
编译完成后,在Release目录下生成的东西拷贝到你要用的地方就好了
2.2 Mac
在Mac上我最终没有安装成功。SPTAG需要gcc编译器,虽然我用gcc替换了Mac自带的clang编译器,最后还是没有安装成功。
- 安装swig
- 安装TBB:同Ubuntu,但是想用gcc编译的话,要在Makefile文件里开头加
compiler=gcc
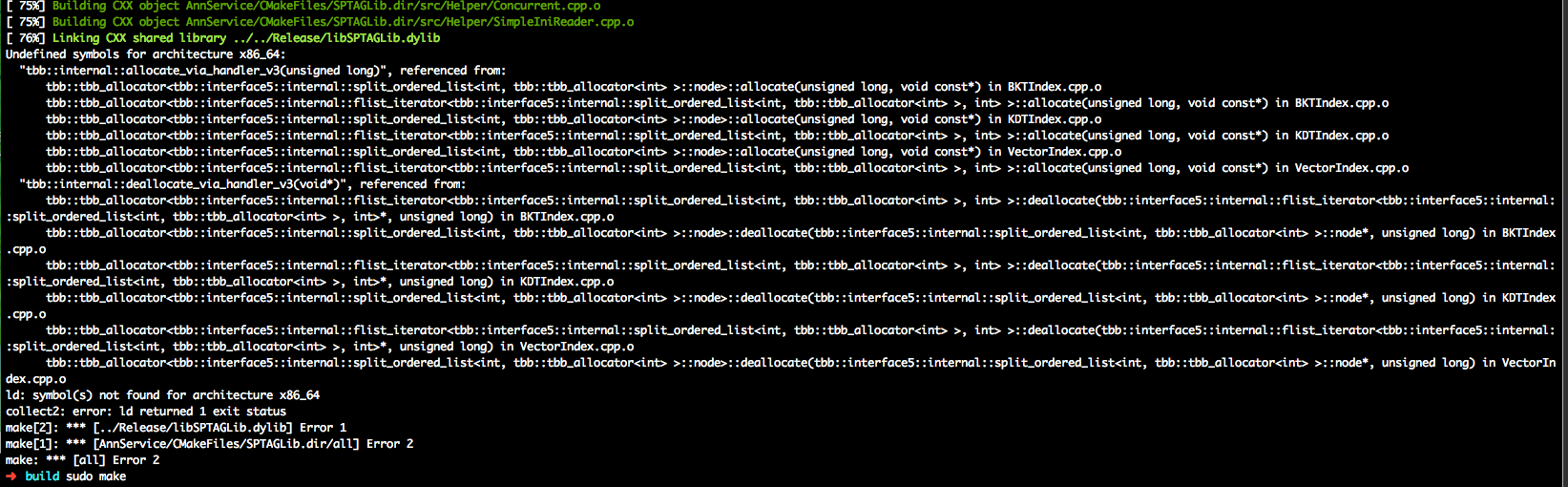
安装SPTAG失败:最后失败在这里一步,不能生成dylib连接文件,不晓得是tbb什么问题,换成gcc编译的tbb还是报相同的问题
3.原理介绍
SPTAG数据结构支持KDT和BKT,距离度量支持L2和cos距离。
- KDT就是
二叉搜索树的多维扩展,介绍,李航的《统计学习方法》也有介绍 - BKT:全称是 balanced k-means tree,目前还未找到资料
注意:SPTAG目前(2019年5月23日)支持的数据类型包括Int8, Int16 and Float (float32),还不支持float64
所以如果你的模型输出是numpy.float64的话,需要用numpy.astype(numpy.float32)强转。代价是可能丢失精度
4 编码
代码没啥好讲的,官网上上已经给了使用方法。其代码下是直接调用了C++库,没有任何其他处理,所以不能通过python去debug。
5.实验
5.1实验记录
- 向量由百度BERT、ERNIE得到,维度768维,数据类型float32
- 使用1w数据,在服务器1(AMD A8 5600k双核四线程, 32G内存)上,线程设置4,build方法用时12分钟
- 使用1w数据,在服务器2(Intel 志强E5 1660 v2 6核12线程, 32G内存)上,线程设置为12,build方法用时275秒,说明多线程对build方法有加速
- 使用200w数据,报错,分别输入第一个100w和第二个100w都没问题,不会报错,故排除数据的问题。猜想一次输入的
数据内存占用不能超过4GB,因为代码是C++写的,验证如下
证实:依据类型,维度,计算得到能输入的数据量为4GB➗每个float32占用的4B➗每个向量768维=1398101.333个向量,结果输入1398101行数据不报错,输入1398102行报错,所以确实是内存限制
5.2问题
- add增量模式不能使用多线程
又发现直接输入100万数据调用add函数时,并没有启用多线程,6核12线程的CPU只有一个核心被占用 - 使用build模式时,多线程性能有问题
我用100w数据build的时,线程设置12,跑了35个小时还没跑完,而add增量模式下,单线程,每次add 1w数据,24个小时不到就完成了。所以这个多线程在数据量较大的情况下,因为同步代价很高而导致并没有加速?
5.3测试结果
百度ERNIE CPU版本,运行10次,平均用时183ms,GPU版本,运行10次,平均用时144ms
谷歌bert CPU下平均用时66ms
sptag,每个问题返回1个答案时,平均用时5ms,每个问题返回3个答案时,平均用时6.3ms




