
1 概述
这次项目里使用110万对QA数据训练一个闲聊模型,epoch=12,batch=64,训练需要36个小时,有点长,而且后期闲聊数据还会增加,所以需要提高训练的速度,很容易想到的就是使用多卡GPU模型。总结如下:
多卡模型分为
数据并行:模型只有一个,每个GPU运行不同的batch,并行计算梯度。根据参数更新方式又分为同步数据并行和异步数据并行。- 同步数据并行:每个batch所有GPU计算完成后,才更新一次参数,收敛速度快,最终训练效果优于异步数据并行方式,但是速度略慢,因为速度取决于性能最差的那个GPU。
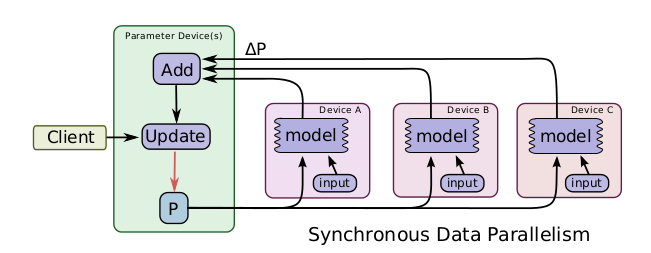
- 异步数据并行:每个GPU计算完梯度后就各自更新,速度快,但是最终模型的性能略低于同步数据并行方式。
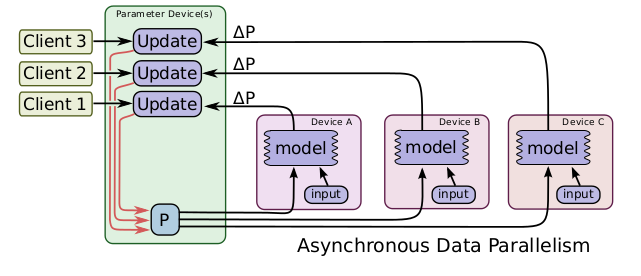
- 同步数据并行:每个batch所有GPU计算完成后,才更新一次参数,收敛速度快,最终训练效果优于异步数据并行方式,但是速度略慢,因为速度取决于性能最差的那个GPU。
模型并行:将不同的模型计算部分部署在不同的GPU上面同时执行。 模型并行: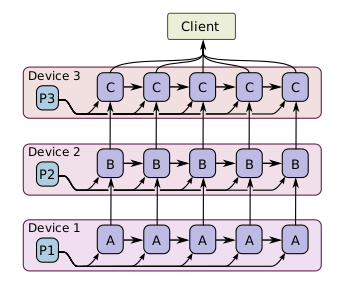
2 实验环境
包依赖
tensorflow-gpu==>1.4.1
jieba
tqdm
python==>3.5
服务器为4张GTX 1080Ti
3 实验步骤
本次实现的是同步数据并行方式。步骤为
- 在CPU下定义
tf.placeholder()和变量tf.get_variable()。变量不要使用
tf.Variable()得到,这个需要配合tf.get_variable_scope().reuse_variables()才能使得变量在多GPU之间重用 - 在各个GPU下定义网络和loss,并把梯度加入到一个全局list中
- 使用保存了全部梯度的list来计算梯度,计算平均梯度,然后更新模型
4 代码
4.1 计算平均梯度函数
代码来自TensorFlow官方cifar10_multi_gpu_train.py
def average_gradients(self, tower_grads):
average_grads = []
for grad_and_vars in zip(*tower_grads):
grads = []
for g, _ in grad_and_vars:
expanded_g = tf.expand_dims(g, 0)
grads.append(expanded_g)
grad = tf.concat(axis=0, values=grads)
grad = tf.reduce_mean(grad, 0)
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads
4.2 网络实现
以伪代码的形式
with tf.Graph().as_default(), tf.device('/cpu:0'):
定义输入占位符tf.placeholder()
定义变量tf.get_variable()
使用tf.split()函数对各个placeholder进行分割,意思是整体的batch会拆分为几个小的batch分别喂给不同的GPU
如self.encoder_inputs_split = tf.split(value=self.encoder_inputs, num_or_size_splits=self.gpu_num, axis=0)
定义优化器
定义全局的梯度的list:multi_grads = []
with tf.variable_scope(tf.get_variable_scope()):
for gpu_id in self.gpu_list:#这里也可以使用range(gpu_num),反正就是一个GPU编号的list
with tf.device('/gpu:%d'%gpu_id), tf.variable_scope(name_or_scope=tf.get_variable_scope(), reuse= gpu_id > 0):
with tf.name_scope('%s_%d' % ('GPU', gpu_id)) as scope:
当前GPU使用的placeholdert:self.encoder_inputs_split[gpu_id]
self.loss = 得到你的loss
# tensorboard显示各GPU的loss
tf.summary.scalar('loss_{}'.format(i), self.loss)
# 重用变量
tf.get_variable_scope().reuse_variables()
self.summary_op = tf.summary.merge_all()
# 计算梯度
gradients = optimizer.compute_gradients(self.loss)
multi_grads.append(gradients)
# 计算平均梯度
grads = self.average_gradients(multi_grads)
self.train_op = optimizer.apply_gradients(grads)
# 保存模型
self.saver = tf.train.Saver(tf.global_variables())
4.3 训练入口
def train(self, sess, batch):
#对于训练阶段,需要执行self.train_op, self.loss, self.summary_op三个op,并传入相应的数据
feed_dict = {self.encoder_inputs: batch.encoder_inputs,
self.encoder_inputs_length: batch.encoder_inputs_length,
self.decoder_targets: batch.decoder_targets,
self.decoder_targets_length: batch.decoder_targets_length,
self.keep_prob_placeholder: 0.5,
self.batch_size: len(batch.encoder_inputs) / len(self.gpu_num),
self.lr_pl: self.learing_rate,
self.mask : batch.masks}
_, loss, summary = sess.run([self.train_op, self.loss, self.summary_op], feed_dict=feed_dict)
return loss, summary
# 实例化模型对象
model = Seq2SeqModel(FLAGS.rnn_size,
FLAGS.num_layers,
FLAGS.embedding_size,
FLAGS.learning_rate,
word2id,
mode='train',
use_attention=True,
beam_search=False,
beam_size=5,
max_gradient_norm=5.0,
gpu_list = gpu_list
)
with tf.Session(config=tf.ConfigProto(gpu_options=tf.GPUOptions(allow_growth=True), allow_soft_placement=True)) as sess:
sess.run(tf.global_variables_initializer())
current_step = 0
# tensorboard用writer
summary_writer = tf.summary.FileWriter(os.path.join('./tensorboard', FLAGS.attempt), graph=sess.graph)
for e in range(epoch_num):
for batch in getNextBatch: # 得到下一个batch的训练数据
loss, summary = model.train(sess, nextBatch)
current_step += 1
summary_writer.add_summary(summary, current_step)
5 遇到的问题
5.1 GPU指定问题
代码中GPU编号依次为0,1,2,3…,即便用如下方式指定了具体要使用GPU编号,这也是能使用for i in range(gpu_num)的原因。
os.environ['CUDA_VISIBLE_DEVICES']='0, 1, 2, 3'
5.2 RNN的batch划分问题
因为我做的是基于seq2seq的一个闲聊模型,所以会用到RNN,遇到了算loss的时候logits和labels的shape的第一维不相等。 比如:假设batch size等于4,使用2张卡,则batch_size_per_gpu=2,现在我有一个batch的样本,样本的目标输出序列的长度分别为{1,2,3,4},则最大长度max_length=4,预处理会把所有样本的目标输出序列补到max_length长度,模型的输入还会包括一个各样本长度的length_list={1,2,3,4}
# decoder的时候的部分代码
training_helper = tf.contrib.seq2seq.TrainingHelper(inputs=decoder_inputs_embedded,
sequence_length=self.decoder_targets_length_split[gpu_id],
time_major=False, name='training_helper')
training_decoder = tf.contrib.seq2seq.BasicDecoder(cell=decoder_cell,
helper=training_helper,
initial_state=decoder_initial_state, output_layer=output_layer)
decoder_outputs, _, _ = tf.contrib.seq2seq.dynamic_decode(decoder=training_decoder,
impute_finished=True,
maximum_iterations=self.max_target_sequence_length)
# 根据输出计算loss和梯度,并定义进行更新的AdamOptimizer和train_op
self.decoder_logits_train = tf.identity(decoder_outputs.rnn_output)
self.decoder_predict_train = tf.argmax(self.decoder_logits_train, axis=-1, name='decoder_pred_train')
# 使用sequence_loss计算loss,这里需要传入之前定义的mask标志
self.loss = tf.contrib.seq2seq.sequence_loss(logits=self.decoder_logits_train,
targets=self.decoder_targets_split[gpu_id],
weights=self.mask_split[gpu_id])
在TrainingHelper里面给了self.decoder_targets_length_split[gpu_id]参数,加入当前我是第一张卡,则其得到的样本目标长度分别为1,2的那个。这个时候如果将这两个样本目标序列真实的长度[1,2]输入进去,这个时候max_length_gpu=2,则得到的输出的shape就是[max_length_gpubatch_size_per_gpu, 词表大小]=[](这里TensorFlow是把两个样本的输出拼接在一起的,所以shape不是[2, batch_size_per_gpu, 词表大小],label也是这样),然后计算loss的时候,label是进行过pad的,所以两个样本拼接后,shape为[4batch_size_per_gpu]=[8]。[4,词表大小]和[8]的第一维度不等,报错。
- 解决方法:输入模型的length_list不使用真实样本里目标序列的长度,而是全部固定为pad之后的长度,即全部设为max_length,即对batch里所有样本,RNN都计算max_length个step。但是这样我们怎么计算真实的loss呢,别担心,最后的
sequence_loss里,不是还有个参数weights吗,样本当前位置如果是pad来的,就给这个位置赋予0权重,那么这个位置的loss就不会被计算到总loss里面去。
5.3 Adam优化器问题
因为Adam优化器内部会定义变量,即便在CPU下定义,也会报优化器重复定义问题
ValueError: Variable embedding/Adam/ already exists, disallowed. Did you mean to set reuse=True or reuse=tf.AUTO_REUSE in VarScope? Originally defined at:
换用其他优化器没有问题,我换成了tf.train.GradientDescentOptimizer(学习率),未报错。
5.4 无GPU支持的kernel
报错内容为:
InvalidArgumentError (see above for traceback): Cannot assign a device for operation ‘GPU_1/gradients/f_acc’: Could not satisfy explicit device specification ‘/device:GPU:1’ because no supported kernel for GPU devices is available.
百度结果为,有些操作不能再GPU上运行,在获得session的时候,增加allow_soft_placement=True参数,让系统自动选择放在哪里计算。
with tf.Session(config=tf.ConfigProto(gpu_options=tf.GPUOptions(allow_growth=True), allow_soft_placement=True)) as sess:
6 命名空间和变量空间
变量的定义是在tf.variable_scope()下,求解梯度过程是在tf.name_scope()下。
tf.variable_scope()下相同的scope_name可以让变量有相同的命名,包括tf.get_variable()得到的变量,还有tf.Variable()的变量,不加tf.get_variable_scope().reuse_variables()的话就不能重用。
所以不同GPU用了不同的tf.name_scope(),全部GPU在同一个tf.variable_scope()下
7 速度对比
我的服务器是4张 GTX 1080 Ti ,每张卡11G显存。速度对比如下:
| 显卡数量 | batch-size | 显存占用情况 | 单个epoch时间 | 加速比 |
|---|---|---|---|---|
| 1 | 64 | 8300 | 1小时15分钟 | - |
| 2 | 128 | 4300 | 45分钟 | 1.67 |
| 4 | 256 | 4300 | 40分钟 | 1.875 |
| 4 | 512 | 8400 | 30分钟 | 2.5 |
第一张GPU的显存占用要比其他GPU多占用几M。可以发现,GPU和内存的交互还是有点慢的
8 参考:
- https://github.com/tensorflow/models/blob/master/tutorials/image/cifar10/cifar10_multi_gpu_train.py(TensorFlow官方的基于cifar10的多卡模型示例,大多数博客都用的这个代码)
- https://www.jianshu.com/p/afb22f123e91 (我的第一版多卡模型参考的这个,流程和官方那个一样,但是实际速度比单卡更慢了,一个epoch要2个小时,后猜测是给所有GPU输入了同样的batch,等效于跑了四个同样的模型,只是初始化位置不一样而已,每次梯度都是平均梯度)
- https://blog.csdn.net/u011961856/article/details/78011270 (这个解决了我如何给不同GPU输入不同batch的疑惑,官方的那个没有相关操作)




